组成部分
- 网页爬取
- 网页信息的整理存储
- 索引的建立
- 搜索的实现
- 结果排序和最后web实现
功能实现
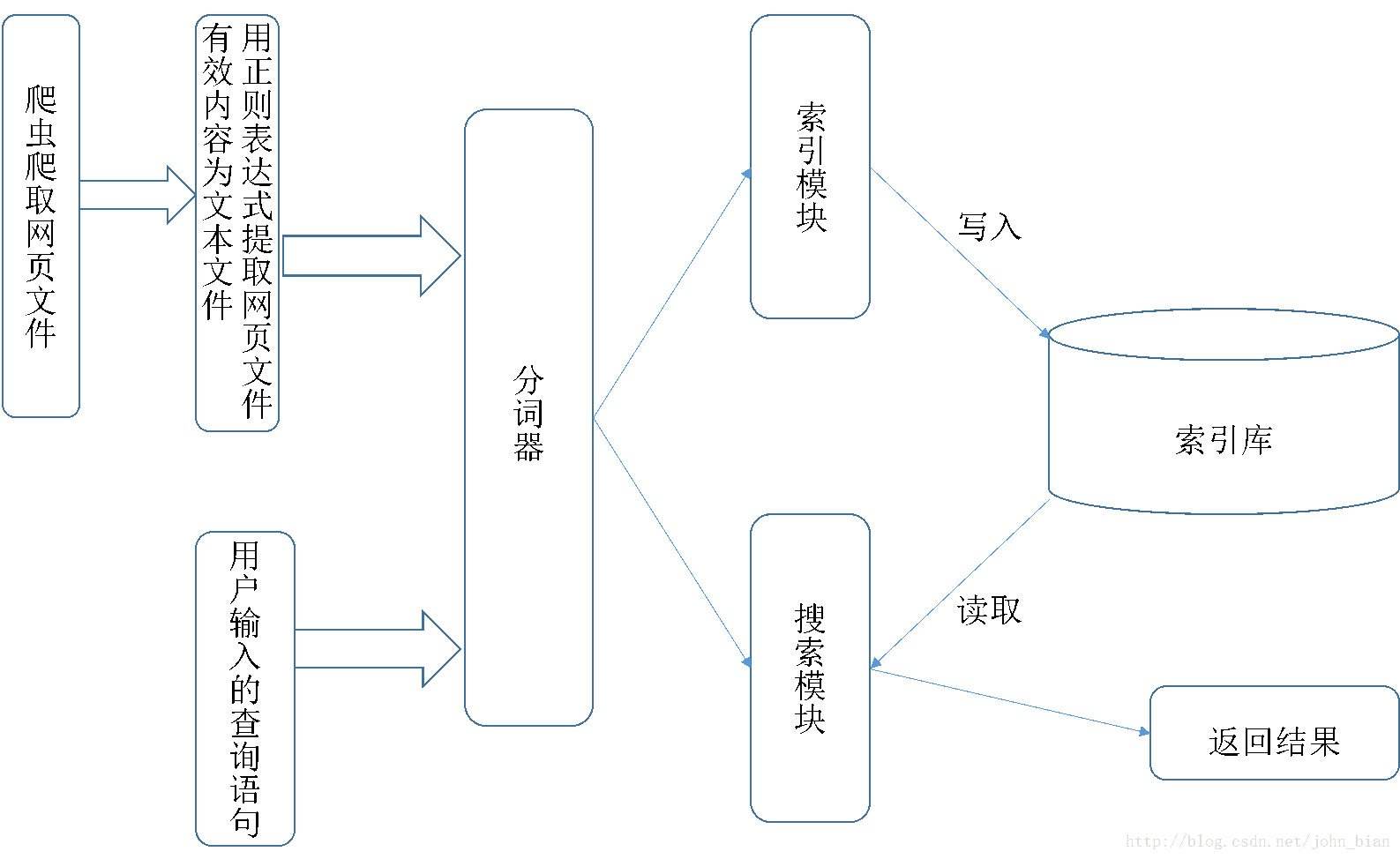
网页爬取与网页信息的提取
爬取网页并保存到本地之后还无法直接使用这些网页文件建立索引,因为这些网页源码中包含大量的HTML标记以及JavaScript脚本代码之类的东西,并且这些数据量远远大于我们所需要的对建立索引来讲有价值的的新闻信息。所以,接下来我们需要分析网页源码,并利用正则表达式对其内容进行提取索引建立
索引的建立使用了Lucene提供的jar包。Document是Lucene建立索引的过程中的一个十分重要的类。Document的意义为文档,在Lucene中,它代表一种逻辑文件。Lucene本身无法对物理文件建立索引,而只能识别并处理Document类型的文件。在某些时候可以将一个Document与一个物理文件进行对应,用一个Document来代替一个物理文件,然而更多的时候,Document和物理的文件没有关系,它作为一种数据源的集合,向Lucene提供原始的要索引的文本内容。Lucene会从Document取出相关的数据源内容,并根据属性配置进行相应的处理
参考资料
- 一个简单的站内搜索引擎的实现
- 实战Lucene